В этом разделе приведены руководства по настройке dbt и адаптера ClickHouse, а также пример использования dbt с ClickHouse на основе общедоступного датасета IMDB. В примере рассматриваются следующие шаги:
- Создание проекта dbt и настройка адаптера ClickHouse.
- Определение модели.
- Обновление модели.
- Создание инкрементальной модели.
- Создание snapshot-модели.
- Использование материализованных представлений.
Эти руководства предназначены для использования в сочетании с остальной документацией, разделом возможностей и конфигураций и справочником по материализациям.
Настройка
Следуйте инструкциям из раздела Настройка dbt и адаптера ClickHouse, чтобы подготовить ваше окружение.
Важно: приведённые ниже инструкции протестированы с Python 3.9.
Подготовка ClickHouse
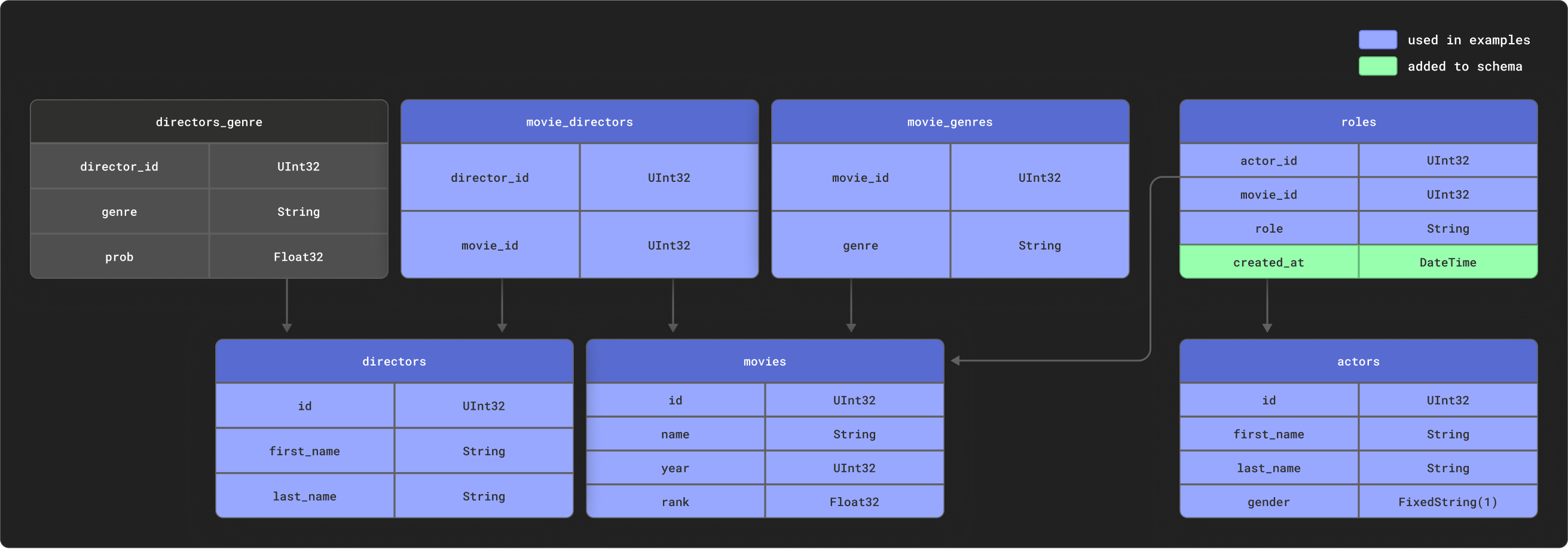
dbt особенно эффективен при моделировании сильно связанных реляционных данных. В качестве примера мы предоставляем небольшой набор данных IMDB со следующей реляционной схемой. Этот набор данных взят из репозитория реляционных наборов данных. Он тривиален по сравнению с типичными схемами, используемыми с dbt, но является удобным для работы примером:
Мы используем подмножество этих таблиц, показанное выше.
Создайте следующие таблицы:
CREATE DATABASE imdb;
CREATE TABLE imdb.actors
(
id UInt32,
first_name String,
last_name String,
gender FixedString(1)
) ENGINE = MergeTree ORDER BY (id, first_name, last_name, gender);
CREATE TABLE imdb.directors
(
id UInt32,
first_name String,
last_name String
) ENGINE = MergeTree ORDER BY (id, first_name, last_name);
CREATE TABLE imdb.genres
(
movie_id UInt32,
genre String
) ENGINE = MergeTree ORDER BY (movie_id, genre);
CREATE TABLE imdb.movie_directors
(
director_id UInt32,
movie_id UInt64
) ENGINE = MergeTree ORDER BY (director_id, movie_id);
CREATE TABLE imdb.movies
(
id UInt32,
name String,
year UInt32,
rank Float32 DEFAULT 0
) ENGINE = MergeTree ORDER BY (id, name, year);
CREATE TABLE imdb.roles
(
actor_id UInt32,
movie_id UInt32,
role String,
created_at DateTime DEFAULT now()
) ENGINE = MergeTree ORDER BY (actor_id, movie_id);
Примечание
Столбец created_at в таблице roles по умолчанию имеет значение now(). Позже мы используем его, чтобы определять инкрементальные обновления наших моделей — см. раздел Incremental Models.
Мы используем функцию s3 для чтения исходных данных из публичных конечных точек и вставки этих данных. Выполните следующие команды, чтобы заполнить таблицы:
INSERT INTO imdb.actors
SELECT *
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/imdb/imdb_ijs_actors.tsv.gz',
'TSVWithNames');
INSERT INTO imdb.directors
SELECT *
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/imdb/imdb_ijs_directors.tsv.gz',
'TSVWithNames');
INSERT INTO imdb.genres
SELECT *
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/imdb/imdb_ijs_movies_genres.tsv.gz',
'TSVWithNames');
INSERT INTO imdb.movie_directors
SELECT *
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/imdb/imdb_ijs_movies_directors.tsv.gz',
'TSVWithNames');
INSERT INTO imdb.movies
SELECT *
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/imdb/imdb_ijs_movies.tsv.gz',
'TSVWithNames');
INSERT INTO imdb.roles(actor_id, movie_id, role)
SELECT actor_id, movie_id, role
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/imdb/imdb_ijs_roles.tsv.gz',
'TSVWithNames');
Время выполнения этих операций может различаться в зависимости от пропускной способности вашего соединения, но каждая из них должна занимать всего несколько секунд. Выполните следующий запрос, чтобы получить сводную статистику по каждому актёру, упорядоченную по числу появлений в фильмах, и убедиться, что данные были успешно загружены:
SELECT id,
any(actor_name) AS name,
uniqExact(movie_id) AS num_movies,
avg(rank) AS avg_rank,
uniqExact(genre) AS unique_genres,
uniqExact(director_name) AS uniq_directors,
max(created_at) AS updated_at
FROM (
SELECT imdb.actors.id AS id,
concat(imdb.actors.first_name, ' ', imdb.actors.last_name) AS actor_name,
imdb.movies.id AS movie_id,
imdb.movies.rank AS rank,
genre,
concat(imdb.directors.first_name, ' ', imdb.directors.last_name) AS director_name,
created_at
FROM imdb.actors
JOIN imdb.roles ON imdb.roles.actor_id = imdb.actors.id
LEFT OUTER JOIN imdb.movies ON imdb.movies.id = imdb.roles.movie_id
LEFT OUTER JOIN imdb.genres ON imdb.genres.movie_id = imdb.movies.id
LEFT OUTER JOIN imdb.movie_directors ON imdb.movie_directors.movie_id = imdb.movies.id
LEFT OUTER JOIN imdb.directors ON imdb.directors.id = imdb.movie_directors.director_id
)
GROUP BY id
ORDER BY num_movies DESC
LIMIT 5;
Ответ должен выглядеть следующим образом:
+------+------------+----------+------------------+-------------+--------------+-------------------+
|id |name |num_movies|avg_rank |unique_genres|uniq_directors|updated_at |
+------+------------+----------+------------------+-------------+--------------+-------------------+
|45332 |Mel Blanc |832 |6.175853582979779 |18 |84 |2022-04-26 14:01:45|
|621468|Bess Flowers|659 |5.57727638854796 |19 |293 |2022-04-26 14:01:46|
|372839|Lee Phelps |527 |5.032976449684617 |18 |261 |2022-04-26 14:01:46|
|283127|Tom London |525 |2.8721716524875673|17 |203 |2022-04-26 14:01:46|
|356804|Bud Osborne |515 |2.0389507108727773|15 |149 |2022-04-26 14:01:46|
+------+------------+----------+------------------+-------------+--------------+-------------------+
В последующих руководствах мы превратим этот запрос в модель, материализовав его в ClickHouse как представление и таблицу в dbt.
Подключение к ClickHouse
-
Создайте проект dbt. В этом примере мы назовём его так же, как наш источник imdb. Когда появится запрос, выберите clickhouse в качестве источника базы данных.
clickhouse-user@clickhouse:~$ dbt init imdb
16:52:40 Running with dbt=1.1.0
Which database would you like to use?
[1] clickhouse
(Don't see the one you want? https://docs.getdbt.com/docs/available-adapters)
Enter a number: 1
16:53:21 No sample profile found for clickhouse.
16:53:21
Your new dbt project "imdb" was created!
For more information on how to configure the profiles.yml file,
please consult the dbt documentation here:
https://docs.getdbt.com/docs/configure-your-profile
-
Перейдите в каталог проекта с помощью команды cd:
-
На этом этапе вам понадобится текстовый редактор по вашему выбору. В примерах ниже мы используем популярный VS Code. Открыв каталог imdb, вы должны увидеть набор файлов yml и sql:
-
Обновите файл dbt_project.yml, чтобы указать нашу первую модель — actor_summary, а также установить профиль clickhouse_imdb.
-
Далее нам нужно предоставить dbt параметры подключения к нашему экземпляру ClickHouse. Добавьте следующее в ~/.dbt/profiles.yml.
clickhouse_imdb:
target: dev
outputs:
dev:
type: clickhouse
schema: imdb_dbt
host: localhost
port: 8123
user: default
password: ''
secure: False
Обратите внимание на необходимость изменить значения user и password. Дополнительные доступные настройки задокументированы здесь.
-
Из каталога imdb выполните команду dbt debug, чтобы проверить, может ли dbt подключиться к ClickHouse.
clickhouse-user@clickhouse:~/imdb$ dbt debug
17:33:53 Running with dbt=1.1.0
dbt version: 1.1.0
python version: 3.10.1
python path: /home/dale/.pyenv/versions/3.10.1/bin/python3.10
os info: Linux-5.13.0-10039-tuxedo-x86_64-with-glibc2.31
Using profiles.yml file at /home/dale/.dbt/profiles.yml
Using dbt_project.yml file at /opt/dbt/imdb/dbt_project.yml
Configuration:
profiles.yml file [OK found and valid]
dbt_project.yml file [OK found and valid]
Required dependencies:
- git [OK found]
Connection:
host: localhost
port: 8123
user: default
schema: imdb_dbt
secure: False
verify: False
Connection test: [OK connection ok]
All checks passed!
Убедитесь, что в ответе содержится строка Connection test: [OK connection ok], что указывает на успешное подключение.
Создание простой материализации представления
При использовании материализации представления модель при каждом запуске пересоздаётся как представление с помощью оператора CREATE VIEW AS в ClickHouse. Это не требует дополнительного хранения данных, но запросы к таким моделям будут выполняться медленнее, чем к материализованным в виде таблиц.
-
Из папки imdb удалите каталог models/example:
clickhouse-user@clickhouse:~/imdb$ rm -rf models/example
-
Создайте новую папку actors внутри каталога models. Здесь мы создадим файлы, каждый из которых представляет модель актёра:
clickhouse-user@clickhouse:~/imdb$ mkdir models/actors
-
Создайте файлы schema.yml и actor_summary.sql в папке models/actors.
clickhouse-user@clickhouse:~/imdb$ touch models/actors/actor_summary.sql
clickhouse-user@clickhouse:~/imdb$ touch models/actors/schema.yml
Файл schema.yml описывает наши таблицы. Впоследствии они будут доступны для использования в макросах. Отредактируйте
models/actors/schema.yml, чтобы он содержал следующее:
version: 2
sources:
- name: imdb
tables:
- name: directors
- name: actors
- name: roles
- name: movies
- name: genres
- name: movie_directors
Файл actors_summary.sql определяет саму модель. Обратите внимание, что в функции config мы также указываем, что модель должна быть материализована как представление в ClickHouse. Наши таблицы ссылаются из файла schema.yml через функцию source, например source('imdb', 'movies') ссылается на таблицу movies в базе данных imdb. Отредактируйте models/actors/actors_summary.sql, чтобы он содержал следующее:
{{ config(materialized='view') }}
with actor_summary as (
SELECT id,
any(actor_name) as name,
uniqExact(movie_id) as num_movies,
avg(rank) as avg_rank,
uniqExact(genre) as genres,
uniqExact(director_name) as directors,
max(created_at) as updated_at
FROM (
SELECT {{ source('imdb', 'actors') }}.id as id,
concat({{ source('imdb', 'actors') }}.first_name, ' ', {{ source('imdb', 'actors') }}.last_name) as actor_name,
{{ source('imdb', 'movies') }}.id as movie_id,
{{ source('imdb', 'movies') }}.rank as rank,
genre,
concat({{ source('imdb', 'directors') }}.first_name, ' ', {{ source('imdb', 'directors') }}.last_name) as director_name,
created_at
FROM {{ source('imdb', 'actors') }}
JOIN {{ source('imdb', 'roles') }} ON {{ source('imdb', 'roles') }}.actor_id = {{ source('imdb', 'actors') }}.id
LEFT OUTER JOIN {{ source('imdb', 'movies') }} ON {{ source('imdb', 'movies') }}.id = {{ source('imdb', 'roles') }}.movie_id
LEFT OUTER JOIN {{ source('imdb', 'genres') }} ON {{ source('imdb', 'genres') }}.movie_id = {{ source('imdb', 'movies') }}.id
LEFT OUTER JOIN {{ source('imdb', 'movie_directors') }} ON {{ source('imdb', 'movie_directors') }}.movie_id = {{ source('imdb', 'movies') }}.id
LEFT OUTER JOIN {{ source('imdb', 'directors') }} ON {{ source('imdb', 'directors') }}.id = {{ source('imdb', 'movie_directors') }}.director_id
)
GROUP BY id
)
select *
from actor_summary
Обратите внимание, что мы включаем столбец updated_at в итоговую actor_summary. Позже мы будем использовать его для инкрементных материализаций.
-
Из каталога imdb выполните команду dbt run.
clickhouse-user@clickhouse:~/imdb$ dbt run
15:05:35 Running with dbt=1.1.0
15:05:35 Found 1 model, 0 tests, 1 snapshot, 0 analyses, 181 macros, 0 operations, 0 seed files, 6 sources, 0 exposures, 0 metrics
15:05:35
15:05:36 Concurrency: 1 threads (target='dev')
15:05:36
15:05:36 1 of 1 START view model imdb_dbt.actor_summary.................................. [RUN]
15:05:37 1 of 1 OK created view model imdb_dbt.actor_summary............................. [OK in 1.00s]
15:05:37
15:05:37 Finished running 1 view model in 1.97s.
15:05:37
15:05:37 Completed successfully
15:05:37
15:05:37 Done. PASS=1 WARN=0 ERROR=0 SKIP=0 TOTAL=1
-
dbt создаст модель в виде представления в ClickHouse, как указано. Теперь мы можем напрямую выполнять запросы к этому представлению. Это представление будет создано в базе данных imdb_dbt — это определяется параметром schema в файле ~/.dbt/profiles.yml в профиле clickhouse_imdb.
+------------------+
|name |
+------------------+
|INFORMATION_SCHEMA|
|default |
|imdb |
|imdb_dbt | <---created by dbt!
|information_schema|
|system |
+------------------+
Выполнив запрос к этому представлению, мы можем воспроизвести результаты нашего предыдущего запроса, используя более простой синтаксис:
SELECT * FROM imdb_dbt.actor_summary ORDER BY num_movies DESC LIMIT 5;
+------+------------+----------+------------------+------+---------+-------------------+
|id |name |num_movies|avg_rank |genres|directors|updated_at |
+------+------------+----------+------------------+------+---------+-------------------+
|45332 |Mel Blanc |832 |6.175853582979779 |18 |84 |2022-04-26 15:26:55|
|621468|Bess Flowers|659 |5.57727638854796 |19 |293 |2022-04-26 15:26:57|
|372839|Lee Phelps |527 |5.032976449684617 |18 |261 |2022-04-26 15:26:56|
|283127|Tom London |525 |2.8721716524875673|17 |203 |2022-04-26 15:26:56|
|356804|Bud Osborne |515 |2.0389507108727773|15 |149 |2022-04-26 15:26:56|
+------+------------+----------+------------------+------+---------+-------------------+
Создание материализованной таблицы
В предыдущем примере наша модель была материализована как представление. Хотя этого может быть достаточно для некоторых запросов, более сложные SELECT-запросы или часто выполняемые запросы могут быть эффективнее материализованы как таблица. Такая материализация полезна для моделей, к которым будут обращаться BI-инструменты, чтобы обеспечить пользователям более высокую скорость работы. Фактически это приводит к тому, что результаты запроса сохраняются как новая таблица с соответствующими накладными расходами на хранение — по сути, выполняется INSERT TO SELECT. Обратите внимание, что эта таблица будет пересоздаваться каждый раз, то есть она не является инкрементальной. Таким образом, большие наборы результатов могут приводить к длительному времени выполнения — см. раздел Ограничения dbt.
-
Измените файл actors_summary.sql так, чтобы параметр materialized был установлен в значение table. Обратите внимание, как определён ORDER BY, и что мы используем табличный движок MergeTree:
{{ config(order_by='(updated_at, id, name)', engine='MergeTree()', materialized='table') }}
-
Из директории imdb выполните команду dbt run. Этот запуск может занять немного больше времени — около 10 секунд на большинстве машин.
clickhouse-user@clickhouse:~/imdb$ dbt run
15:13:27 Running with dbt=1.1.0
15:13:27 Found 1 model, 0 tests, 1 snapshot, 0 analyses, 181 macros, 0 operations, 0 seed files, 6 sources, 0 exposures, 0 metrics
15:13:27
15:13:28 Concurrency: 1 threads (target='dev')
15:13:28
15:13:28 1 of 1 START table model imdb_dbt.actor_summary................................. [RUN]
15:13:37 1 of 1 OK created table model imdb_dbt.actor_summary............................ [OK in 9.22s]
15:13:37
15:13:37 Finished running 1 table model in 10.20s.
15:13:37
15:13:37 Completed successfully
15:13:37
15:13:37 Done. PASS=1 WARN=0 ERROR=0 SKIP=0 TOTAL=1
-
Подтвердите создание таблицы imdb_dbt.actor_summary:
SHOW CREATE TABLE imdb_dbt.actor_summary;
Вы должны увидеть таблицу с соответствующими типами данных:
+----------------------------------------
|statement
+----------------------------------------
|CREATE TABLE imdb_dbt.actor_summary
|(
|`id` UInt32,
|`first_name` String,
|`last_name` String,
|`num_movies` UInt64,
|`updated_at` DateTime
|)
|ENGINE = MergeTree
|ORDER BY (id, first_name, last_name)
+----------------------------------------
-
Убедитесь, что результаты из этой таблицы соответствуют предыдущим результатам. Обратите внимание на заметное улучшение времени ответа теперь, когда модель материализована как таблица:
SELECT * FROM imdb_dbt.actor_summary ORDER BY num_movies DESC LIMIT 5;
+------+------------+----------+------------------+------+---------+-------------------+
|id |name |num_movies|avg_rank |genres|directors|updated_at |
+------+------------+----------+------------------+------+---------+-------------------+
|45332 |Mel Blanc |832 |6.175853582979779 |18 |84 |2022-04-26 15:26:55|
|621468|Bess Flowers|659 |5.57727638854796 |19 |293 |2022-04-26 15:26:57|
|372839|Lee Phelps |527 |5.032976449684617 |18 |261 |2022-04-26 15:26:56|
|283127|Tom London |525 |2.8721716524875673|17 |203 |2022-04-26 15:26:56|
|356804|Bud Osborne |515 |2.0389507108727773|15 |149 |2022-04-26 15:26:56|
+------+------------+----------+------------------+------+---------+-------------------+
При необходимости выполняйте и другие запросы к этой модели. Например, какие актёры снимаются в фильмах с наивысшим рейтингом и имеют более 5 появлений?
SELECT * FROM imdb_dbt.actor_summary WHERE num_movies > 5 ORDER BY avg_rank DESC LIMIT 10;
Создание инкрементальной материализации
В предыдущем примере была создана таблица для материализации модели. Эта таблица будет заново создаваться при каждом выполнении dbt. Для больших результирующих наборов или сложных трансформаций это может быть невыполнимо и крайне затратно. Чтобы решить эту задачу и сократить время сборки, dbt предлагает инкрементальные материализации (Incremental). Они позволяют dbt вставлять или обновлять записи в таблице, начиная с последнего запуска, что делает этот подход подходящим для событийных данных. Под капотом создаётся временная таблица со всеми обновлёнными записями, после чего все нетронутые записи, а также обновлённые записи вставляются в новую целевую таблицу. В результате для больших результирующих наборов возникают схожие ограничения, как и для табличной модели.
Чтобы обойти эти ограничения для больших наборов, адаптер поддерживает режим inserts_only, при котором все обновления вставляются в целевую таблицу без создания временной таблицы (подробнее об этом ниже).
Для иллюстрации этого примера мы добавим актёра «Clicky McClickHouse», который появится в невероятных 910 фильмах — гарантируя, что он снимется в большем количестве картин, чем даже Мел Бланк.
-
Сначала изменяем модель, задав ей тип incremental. Для этого требуется:
- unique_key - Чтобы адаптер мог однозначно идентифицировать строки, необходимо указать unique_key — в данном случае достаточно поля
id из нашего запроса. Это гарантирует отсутствие дубликатов строк в нашей материализованной таблице. Дополнительные сведения об ограничениях уникальности см. здесь.
- Incremental filter - Нам также нужно указать dbt, как определять, какие строки изменились при инкрементальном запуске. Это достигается за счёт задания выражения дельты. Обычно для данных о событиях используется метка времени, поэтому мы применяем поле метки времени updated_at. Этот столбец, который по умолчанию принимает значение now() при вставке строк, позволяет идентифицировать новые строки. Дополнительно нам нужно обработать альтернативный случай, когда добавляются новые актёры. Используя переменную
{{this}} для обозначения существующей материализованной таблицы, мы получаем выражение where id > (select max(id) from {{ this }}) or updated_at > (select max(updated_at) from {{this}}). Мы оборачиваем его в условие {% if is_incremental() %}, гарантируя, что оно используется только при инкрементальных запусках, а не при первоначальном создании таблицы. Дополнительные сведения о фильтрации строк для инкрементальных моделей см. это обсуждение в документации dbt.
Обновите файл actor_summary.sql следующим образом:
{{ config(order_by='(updated_at, id, name)', engine='MergeTree()', materialized='incremental', unique_key='id') }}
with actor_summary as (
SELECT id,
any(actor_name) as name,
uniqExact(movie_id) as num_movies,
avg(rank) as avg_rank,
uniqExact(genre) as genres,
uniqExact(director_name) as directors,
max(created_at) as updated_at
FROM (
SELECT {{ source('imdb', 'actors') }}.id as id,
concat({{ source('imdb', 'actors') }}.first_name, ' ', {{ source('imdb', 'actors') }}.last_name) as actor_name,
{{ source('imdb', 'movies') }}.id as movie_id,
{{ source('imdb', 'movies') }}.rank as rank,
genre,
concat({{ source('imdb', 'directors') }}.first_name, ' ', {{ source('imdb', 'directors') }}.last_name) as director_name,
created_at
FROM {{ source('imdb', 'actors') }}
JOIN {{ source('imdb', 'roles') }} ON {{ source('imdb', 'roles') }}.actor_id = {{ source('imdb', 'actors') }}.id
LEFT OUTER JOIN {{ source('imdb', 'movies') }} ON {{ source('imdb', 'movies') }}.id = {{ source('imdb', 'roles') }}.movie_id
LEFT OUTER JOIN {{ source('imdb', 'genres') }} ON {{ source('imdb', 'genres') }}.movie_id = {{ source('imdb', 'movies') }}.id
LEFT OUTER JOIN {{ source('imdb', 'movie_directors') }} ON {{ source('imdb', 'movie_directors') }}.movie_id = {{ source('imdb', 'movies') }}.id
LEFT OUTER JOIN {{ source('imdb', 'directors') }} ON {{ source('imdb', 'directors') }}.id = {{ source('imdb', 'movie_directors') }}.director_id
)
GROUP BY id
)
select *
from actor_summary
{% if is_incremental() %}
-- this filter will only be applied on an incremental run
where id > (select max(id) from {{ this }}) or updated_at > (select max(updated_at) from {{this}})
{% endif %}
Обратите внимание, что наша модель будет обновляться только при изменениях (обновлениях и добавлениях) в таблицах roles и actors. Чтобы обрабатывать все таблицы, рекомендуется разделить эту модель на несколько подмоделей — каждая со своими собственными инкрементальными критериями. Эти модели, в свою очередь, могут ссылаться друг на друга и связываться между собой. Для получения дополнительной информации о кросс-ссылках между моделями смотрите здесь.
-
Выполните dbt run и проверьте результирующую таблицу:
clickhouse-user@clickhouse:~/imdb$ dbt run
15:33:34 Running with dbt=1.1.0
15:33:34 Found 1 model, 0 tests, 1 snapshot, 0 analyses, 181 macros, 0 operations, 0 seed files, 6 sources, 0 exposures, 0 metrics
15:33:34
15:33:35 Concurrency: 1 threads (target='dev')
15:33:35
15:33:35 1 of 1 START incremental model imdb_dbt.actor_summary........................... [RUN]
15:33:41 1 of 1 OK created incremental model imdb_dbt.actor_summary...................... [OK in 6.33s]
15:33:41
15:33:41 Finished running 1 incremental model in 7.30s.
15:33:41
15:33:41 Completed successfully
15:33:41
15:33:41 Done. PASS=1 WARN=0 ERROR=0 SKIP=0 TOTAL=1
SELECT * FROM imdb_dbt.actor_summary ORDER BY num_movies DESC LIMIT 5;
+------+------------+----------+------------------+------+---------+-------------------+
|id |name |num_movies|avg_rank |genres|directors|updated_at |
+------+------------+----------+------------------+------+---------+-------------------+
|45332 |Mel Blanc |832 |6.175853582979779 |18 |84 |2022-04-26 15:26:55|
|621468|Bess Flowers|659 |5.57727638854796 |19 |293 |2022-04-26 15:26:57|
|372839|Lee Phelps |527 |5.032976449684617 |18 |261 |2022-04-26 15:26:56|
|283127|Tom London |525 |2.8721716524875673|17 |203 |2022-04-26 15:26:56|
|356804|Bud Osborne |515 |2.0389507108727773|15 |149 |2022-04-26 15:26:56|
+------+------------+----------+------------------+------+---------+-------------------+
-
Теперь добавим данные в нашу модель, чтобы продемонстрировать инкрементальное обновление. Добавьте актёра «Clicky McClickHouse» в таблицу actors:
INSERT INTO imdb.actors VALUES (845466, 'Clicky', 'McClickHouse', 'M');
-
Пусть «Clicky» снимется в 910 случайных фильмах:
INSERT INTO imdb.roles
SELECT now() as created_at, 845466 as actor_id, id as movie_id, 'Himself' as role
FROM imdb.movies
LIMIT 910 OFFSET 10000;
-
Подтвердите, что он действительно теперь является актером с наибольшим количеством появлений, выполнив запрос к базовой исходной таблице, минуя все модели dbt:
SELECT id,
any(actor_name) as name,
uniqExact(movie_id) as num_movies,
avg(rank) as avg_rank,
uniqExact(genre) as unique_genres,
uniqExact(director_name) as uniq_directors,
max(created_at) as updated_at
FROM (
SELECT imdb.actors.id as id,
concat(imdb.actors.first_name, ' ', imdb.actors.last_name) as actor_name,
imdb.movies.id as movie_id,
imdb.movies.rank as rank,
genre,
concat(imdb.directors.first_name, ' ', imdb.directors.last_name) as director_name,
created_at
FROM imdb.actors
JOIN imdb.roles ON imdb.roles.actor_id = imdb.actors.id
LEFT OUTER JOIN imdb.movies ON imdb.movies.id = imdb.roles.movie_id
LEFT OUTER JOIN imdb.genres ON imdb.genres.movie_id = imdb.movies.id
LEFT OUTER JOIN imdb.movie_directors ON imdb.movie_directors.movie_id = imdb.movies.id
LEFT OUTER JOIN imdb.directors ON imdb.directors.id = imdb.movie_directors.director_id
)
GROUP BY id
ORDER BY num_movies DESC
LIMIT 2;
+------+-------------------+----------+------------------+------+---------+-------------------+
|id |name |num_movies|avg_rank |genres|directors|updated_at |
+------+-------------------+----------+------------------+------+---------+-------------------+
|845466|Clicky McClickHouse|910 |1.4687938697032283|21 |662 |2022-04-26 16:20:36|
|45332 |Mel Blanc |909 |5.7884792542982515|19 |148 |2022-04-26 16:17:42|
+------+-------------------+----------+------------------+------+---------+-------------------+
-
Выполните dbt run и убедитесь, что наша модель обновилась и соответствует приведённым выше результатам:
clickhouse-user@clickhouse:~/imdb$ dbt run
16:12:16 Running with dbt=1.1.0
16:12:16 Found 1 model, 0 tests, 1 snapshot, 0 analyses, 181 macros, 0 operations, 0 seed files, 6 sources, 0 exposures, 0 metrics
16:12:16
16:12:17 Concurrency: 1 threads (target='dev')
16:12:17
16:12:17 1 of 1 START incremental model imdb_dbt.actor_summary........................... [RUN]
16:12:24 1 of 1 OK created incremental model imdb_dbt.actor_summary...................... [OK in 6.82s]
16:12:24
16:12:24 Finished running 1 incremental model in 7.79s.
16:12:24
16:12:24 Completed successfully
16:12:24
16:12:24 Done. PASS=1 WARN=0 ERROR=0 SKIP=0 TOTAL=1
SELECT * FROM imdb_dbt.actor_summary ORDER BY num_movies DESC LIMIT 2;
+------+-------------------+----------+------------------+------+---------+-------------------+
|id |name |num_movies|avg_rank |genres|directors|updated_at |
+------+-------------------+----------+------------------+------+---------+-------------------+
|845466|Clicky McClickHouse|910 |1.4687938697032283|21 |662 |2022-04-26 16:20:36|
|45332 |Mel Blanc |909 |5.7884792542982515|19 |148 |2022-04-26 16:17:42|
+------+-------------------+----------+------------------+------+---------+-------------------+
Внутреннее устройство
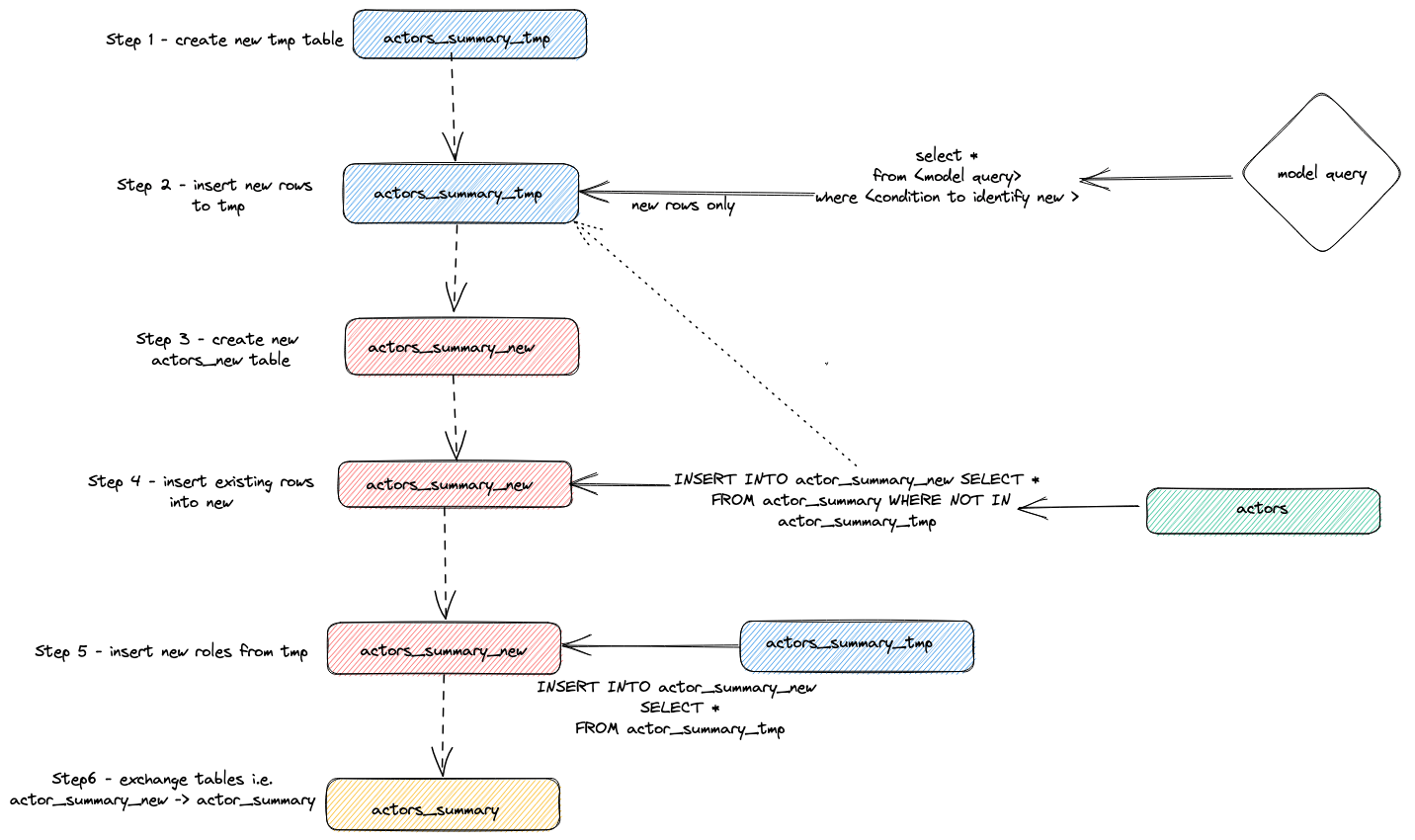
Мы можем определить, какие запросы выполнялись для реализации описанного выше инкрементального обновления, обратившись к журналу запросов ClickHouse.
SELECT event_time, query FROM system.query_log WHERE type='QueryStart' AND query LIKE '%dbt%'
AND event_time > subtractMinutes(now(), 15) ORDER BY event_time LIMIT 100;
Отрегулируйте приведённый выше запрос под период выполнения. Проверку результата оставляем пользователю, но выделим общую стратегию, которую адаптер использует для выполнения инкрементальных обновлений:
- Адаптер создаёт временную таблицу
actor_sumary__dbt_tmp. Строки с внесёнными изменениями построчно записываются (streamed) в эту таблицу.
- Создаётся новая таблица
actor_summary_new. Строки из старой таблицы по очереди переносятся (streamed) из старой в новую с проверкой на отсутствие идентификаторов строк во временной таблице. Это эффективно обрабатывает обновления и дубликаты.
- Результаты из временной таблицы построчно записываются в новую таблицу
actor_summary.
- Наконец, новая таблица атомарно обменивается со старой версией с помощью оператора
EXCHANGE TABLES. Старая и временная таблицы затем удаляются.
Это показано ниже:
Такая стратегия может создавать сложности на очень больших моделях. Для получения дополнительной информации см. раздел Limitations.
Стратегия добавления (режим только вставок)
Чтобы преодолеть ограничения больших наборов данных в инкрементальных моделях, адаптер использует параметр конфигурации dbt incremental_strategy. Его можно установить в значение append. При таком значении обновлённые строки вставляются непосредственно в целевую таблицу (т.е. imdb_dbt.actor_summary), и временная таблица не создаётся.
Примечание: режим только добавления требует, чтобы ваши данные были неизменяемыми или чтобы дубликаты были допустимы. Если вам нужна инкрементальная модель таблицы с поддержкой изменённых строк, не используйте этот режим!
Чтобы продемонстрировать этот режим, мы добавим ещё одного актёра и повторно выполним dbt run с incremental_strategy='append'.
-
Настройте режим только добавления в actor_summary.sql:
{{ config(order_by='(updated_at, id, name)', engine='MergeTree()', materialized='incremental', unique_key='id', incremental_strategy='append') }}
-
Добавим ещё одного известного актёра — Danny DeBito
INSERT INTO imdb.actors VALUES (845467, 'Danny', 'DeBito', 'M');
-
Снимем Danny в 920 случайных фильмах.
INSERT INTO imdb.roles
SELECT now() as created_at, 845467 as actor_id, id as movie_id, 'Himself' as role
FROM imdb.movies
LIMIT 920 OFFSET 10000;
-
Выполните dbt run и убедитесь, что Danny был добавлен в таблицу actor-summary
clickhouse-user@clickhouse:~/imdb$ dbt run
16:12:16 Running with dbt=1.1.0
16:12:16 Found 1 model, 0 tests, 1 snapshot, 0 analyses, 186 macros, 0 operations, 0 seed files, 6 sources, 0 exposures, 0 metrics
16:12:16
16:12:17 Concurrency: 1 threads (target='dev')
16:12:17
16:12:17 1 of 1 START incremental model imdb_dbt.actor_summary........................... [RUN]
16:12:24 1 of 1 OK created incremental model imdb_dbt.actor_summary...................... [OK in 0.17s]
16:12:24
16:12:24 Finished running 1 incremental model in 0.19s.
16:12:24
16:12:24 Completed successfully
16:12:24
16:12:24 Done. PASS=1 WARN=0 ERROR=0 SKIP=0 TOTAL=1
SELECT * FROM imdb_dbt.actor_summary ORDER BY num_movies DESC LIMIT 3;
+------+-------------------+----------+------------------+------+---------+-------------------+
|id |name |num_movies|avg_rank |genres|directors|updated_at |
+------+-------------------+----------+------------------+------+---------+-------------------+
|845467|Danny DeBito |920 |1.4768987303293204|21 |670 |2022-04-26 16:22:06|
|845466|Clicky McClickHouse|910 |1.4687938697032283|21 |662 |2022-04-26 16:20:36|
|45332 |Mel Blanc |909 |5.7884792542982515|19 |148 |2022-04-26 16:17:42|
+------+-------------------+----------+------------------+------+---------+-------------------+
Обратите внимание, насколько быстрее был этот инкрементальный запуск по сравнению с вставкой «Clicky».
Если снова посмотреть на таблицу query_log, можно увидеть различия между двумя инкрементальными запусками:
INSERT INTO imdb_dbt.actor_summary ("id", "name", "num_movies", "avg_rank", "genres", "directors", "updated_at")
WITH actor_summary AS (
SELECT id,
any(actor_name) AS name,
uniqExact(movie_id) AS num_movies,
avg(rank) AS avg_rank,
uniqExact(genre) AS genres,
uniqExact(director_name) AS directors,
max(created_at) AS updated_at
FROM (
SELECT imdb.actors.id AS id,
concat(imdb.actors.first_name, ' ', imdb.actors.last_name) AS actor_name,
imdb.movies.id AS movie_id,
imdb.movies.rank AS rank,
genre,
concat(imdb.directors.first_name, ' ', imdb.directors.last_name) AS director_name,
created_at
FROM imdb.actors
JOIN imdb.roles ON imdb.roles.actor_id = imdb.actors.id
LEFT OUTER JOIN imdb.movies ON imdb.movies.id = imdb.roles.movie_id
LEFT OUTER JOIN imdb.genres ON imdb.genres.movie_id = imdb.movies.id
LEFT OUTER JOIN imdb.movie_directors ON imdb.movie_directors.movie_id = imdb.movies.id
LEFT OUTER JOIN imdb.directors ON imdb.directors.id = imdb.movie_directors.director_id
)
GROUP BY id
)
SELECT *
FROM actor_summary
-- this filter will only be applied on an incremental run
WHERE id > (SELECT max(id) FROM imdb_dbt.actor_summary) OR updated_at > (SELECT max(updated_at) FROM imdb_dbt.actor_summary)
В этом прогоне непосредственно в таблицу imdb_dbt.actor_summary добавляются только новые строки, при этом создание таблицы не выполняется.
Режим удаления и вставки (экспериментальный)
INSERT INTO imdb_dbt.actor_summary ("id", "name", "num_movies", "avg_rank", "genres", "directors", "updated_at")
WITH actor_summary AS (
SELECT id,
any(actor_name) AS name,
uniqExact(movie_id) AS num_movies,
avg(rank) AS avg_rank,
uniqExact(genre) AS genres,
uniqExact(director_name) AS directors,
max(created_at) AS updated_at
FROM (
SELECT imdb.actors.id AS id,
concat(imdb.actors.first_name, ' ', imdb.actors.last_name) AS actor_name,
imdb.movies.id AS movie_id,
imdb.movies.rank AS rank,
genre,
concat(imdb.directors.first_name, ' ', imdb.directors.last_name) AS director_name,
created_at
FROM imdb.actors
JOIN imdb.roles ON imdb.roles.actor_id = imdb.actors.id
LEFT OUTER JOIN imdb.movies ON imdb.movies.id = imdb.roles.movie_id
LEFT OUTER JOIN imdb.genres ON imdb.genres.movie_id = imdb.movies.id
LEFT OUTER JOIN imdb.movie_directors ON imdb.movie_directors.movie_id = imdb.movies.id
LEFT OUTER JOIN imdb.directors ON imdb.directors.id = imdb.movie_directors.director_id
)
GROUP BY id
)
SELECT *
FROM actor_summary
-- this filter will only be applied on an incremental run
WHERE id > (SELECT max(id) FROM imdb_dbt.actor_summary) OR updated_at > (SELECT max(updated_at) FROM imdb_dbt.actor_summary)
В этом прогоне непосредственно в таблицу imdb_dbt.actor_summary добавляются только новые строки, при этом создание таблицы не выполняется.
режим delete+insert (экспериментальный)
Традиционно ClickHouse имел лишь ограниченную поддержку операций обновления и удаления в виде асинхронных Mutations. Эти операции могут быть крайне ресурсоёмкими по вводу-выводу, и, как правило, их следует избегать.
В ClickHouse 22.8 были добавлены облегчённые удаления, а в ClickHouse 25.7 — облегчённые обновления. С появлением этих возможностей изменения, выполняемые одиночными запросами обновления, даже при асинхронной материализации, будут происходить мгновенно с точки зрения пользователя.
Этот режим может быть настроен для модели с помощью параметра incremental_strategy, то есть:
{{ config(order_by='(updated_at, id, name)', engine='MergeTree()', materialized='incremental', unique_key='id', incremental_strategy='delete+insert') }}
Эта стратегия работает напрямую с целевой таблицей модели, поэтому если во время операции произойдет ошибка, данные в инкрементальной модели, скорее всего, окажутся в некорректном состоянии — атомарного обновления нет.
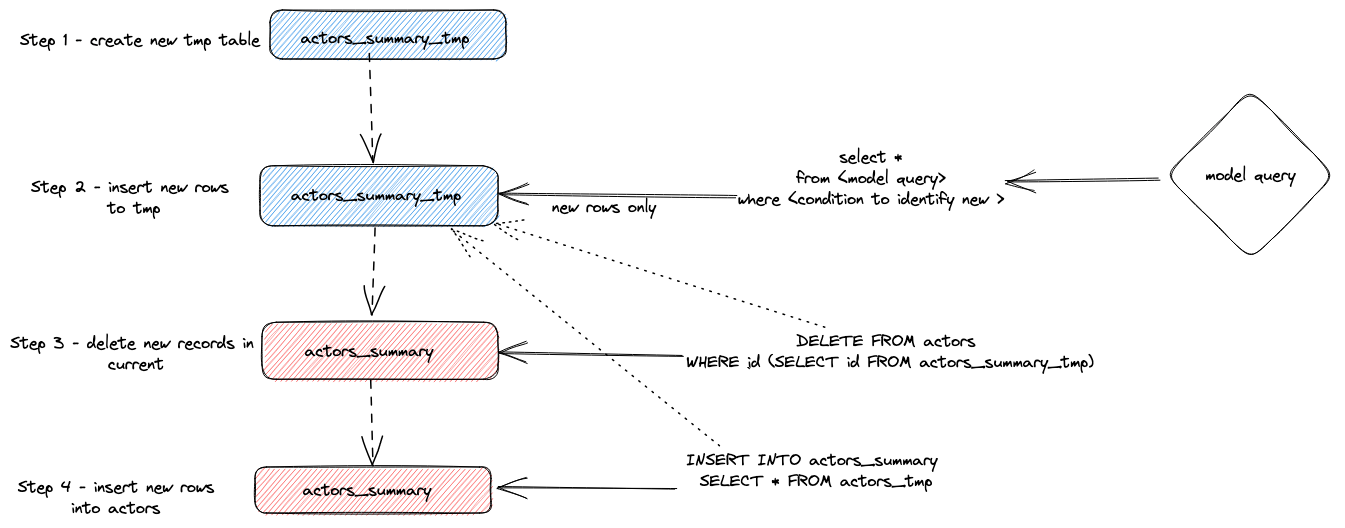
Вкратце, этот подход выполняет следующее:
- Адаптер создает временную таблицу
actor_sumary__dbt_tmp. Строки, в которых были изменения, потоково записываются в эту таблицу.
- Выполняется
DELETE по текущей таблице actor_summary. Строки удаляются по id из actor_sumary__dbt_tmp.
- Строки из
actor_sumary__dbt_tmp вставляются в actor_summary с помощью INSERT INTO actor_summary SELECT * FROM actor_sumary__dbt_tmp.
Этот процесс показан ниже:
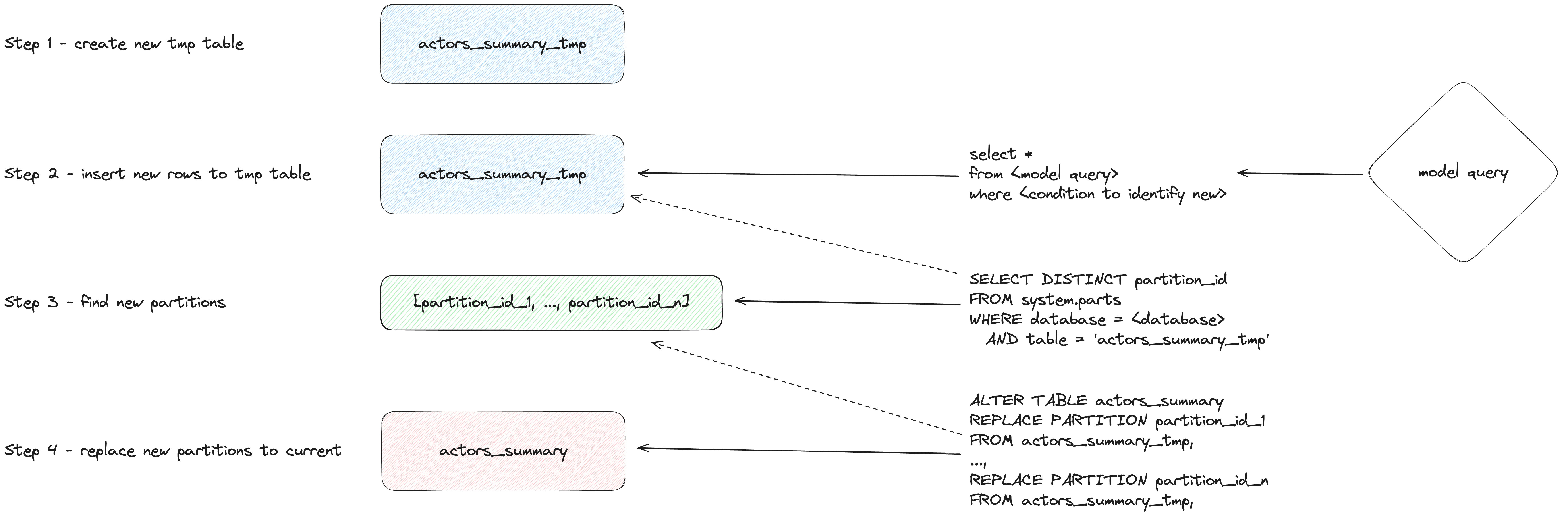
режим insert_overwrite (экспериментальный)
Выполняет следующие шаги:
- Создать staging (временную) таблицу с той же структурой, что и у отношения инкрементальной модели:
CREATE TABLE {staging} AS {target}.
- Вставить только новые записи (результат SELECT) во временную таблицу.
- Заменить в целевой таблице только те партиции, которые присутствуют во временной таблице.
У этого подхода есть следующие преимущества:
- Он быстрее, чем стратегия по умолчанию, потому что не копирует всю таблицу.
- Он безопаснее других стратегий, потому что не изменяет исходную таблицу до тех пор, пока операция INSERT не завершится успешно: в случае промежуточного сбоя исходная таблица не изменяется.
- Он реализует практику data engineering «неизменяемости партиций» (partitions immutability), что упрощает инкрементальную и параллельную обработку данных, откаты и т. д.
Создание снимка
Снимки dbt позволяют зафиксировать изменения изменяемой модели во времени. Это, в свою очередь, позволяет выполнять запросы к моделям на состояние в конкретный момент времени, когда аналитики могут «оглядываться назад» и просматривать предыдущее состояние модели. Это достигается с помощью измерений типа 2 (Slowly Changing Dimensions), где столбцы from и to фиксируют период, в течение которого строка считалась актуальной. Эта функциональность поддерживается адаптером ClickHouse и продемонстрирована ниже.
В этом примере предполагается, что вы завершили шаг Creating an Incremental Table Model. Убедитесь, что ваш actor_summary.sql не устанавливает inserts_only=True. Ваш models/actor_summary.sql должен выглядеть следующим образом:
{{ config(order_by='(updated_at, id, name)', engine='MergeTree()', materialized='incremental', unique_key='id') }}
with actor_summary as (
SELECT id,
any(actor_name) as name,
uniqExact(movie_id) as num_movies,
avg(rank) as avg_rank,
uniqExact(genre) as genres,
uniqExact(director_name) as directors,
max(created_at) as updated_at
FROM (
SELECT {{ source('imdb', 'actors') }}.id as id,
concat({{ source('imdb', 'actors') }}.first_name, ' ', {{ source('imdb', 'actors') }}.last_name) as actor_name,
{{ source('imdb', 'movies') }}.id as movie_id,
{{ source('imdb', 'movies') }}.rank as rank,
genre,
concat({{ source('imdb', 'directors') }}.first_name, ' ', {{ source('imdb', 'directors') }}.last_name) as director_name,
created_at
FROM {{ source('imdb', 'actors') }}
JOIN {{ source('imdb', 'roles') }} ON {{ source('imdb', 'roles') }}.actor_id = {{ source('imdb', 'actors') }}.id
LEFT OUTER JOIN {{ source('imdb', 'movies') }} ON {{ source('imdb', 'movies') }}.id = {{ source('imdb', 'roles') }}.movie_id
LEFT OUTER JOIN {{ source('imdb', 'genres') }} ON {{ source('imdb', 'genres') }}.movie_id = {{ source('imdb', 'movies') }}.id
LEFT OUTER JOIN {{ source('imdb', 'movie_directors') }} ON {{ source('imdb', 'movie_directors') }}.movie_id = {{ source('imdb', 'movies') }}.id
LEFT OUTER JOIN {{ source('imdb', 'directors') }} ON {{ source('imdb', 'directors') }}.id = {{ source('imdb', 'movie_directors') }}.director_id
)
GROUP BY id
)
select *
from actor_summary
{% if is_incremental() %}
-- this filter will only be applied on an incremental run
where id > (select max(id) from {{ this }}) or updated_at > (select max(updated_at) from {{this}})
{% endif %}
-
Создайте файл actor_summary в директории snapshots.
touch snapshots/actor_summary.sql
-
Обновите содержимое файла actor_summary.sql следующим кодом:
{% snapshot actor_summary_snapshot %}
{{
config(
target_schema='snapshots',
unique_key='id',
strategy='timestamp',
updated_at='updated_at',
)
}}
select * from {{ref('actor_summary')}}
{% endsnapshot %}
Несколько замечаний относительно этого содержимого:
- Оператор select определяет результаты, по которым вы хотите строить снимки (snapshots) во времени. Функция ref используется для ссылки на ранее созданную модель actor_summary.
- Нам необходим столбец с типом timestamp для фиксации изменений записей. Наш столбец updated_at (см. Creating an Incremental Table Model) можно использовать здесь. Параметр strategy указывает, что мы используем временную метку для обозначения обновлений, а параметр updated_at определяет столбец, который следует использовать. Если такого столбца нет в вашей модели, вы можете вместо этого использовать check strategy. Этот подход значительно менее эффективен и требует от пользователя указать список столбцов для сравнения. dbt сравнивает текущие и исторические значения этих столбцов, фиксируя любые изменения (или не делая ничего, если значения идентичны).
-
Выполните команду dbt snapshot.
clickhouse-user@clickhouse:~/imdb$ dbt snapshot
13:26:23 Running with dbt=1.1.0
13:26:23 Found 1 model, 0 tests, 1 snapshot, 0 analyses, 181 macros, 0 operations, 0 seed files, 3 sources, 0 exposures, 0 metrics
13:26:23
13:26:25 Concurrency: 1 threads (target='dev')
13:26:25
13:26:25 1 of 1 START snapshot snapshots.actor_summary_snapshot...................... [RUN]
13:26:25 1 of 1 OK snapshotted snapshots.actor_summary_snapshot...................... [OK in 0.79s]
13:26:25
13:26:25 Finished running 1 snapshot in 2.11s.
13:26:25
13:26:25 Completed successfully
13:26:25
13:26:25 Done. PASS=1 WARN=0 ERROR=0 SKIP=0 TOTAL=1
Обратите внимание, что в базе данных snapshots (определяется параметром target_schema) была создана таблица actor_summary_snapshot.
-
При выборочной выборке этих данных вы увидите, что dbt добавил столбцы dbt_valid_from и dbt_valid_to. Для последнего значения установлены в null. Последующие запуски будут обновлять их.
SELECT id, name, num_movies, dbt_valid_from, dbt_valid_to FROM snapshots.actor_summary_snapshot ORDER BY num_movies DESC LIMIT 5;
+------+----------+------------+----------+-------------------+------------+
|id |first_name|last_name |num_movies|dbt_valid_from |dbt_valid_to|
+------+----------+------------+----------+-------------------+------------+
|845467|Danny |DeBito |920 |2022-05-25 19:33:32|NULL |
|845466|Clicky |McClickHouse|910 |2022-05-25 19:32:34|NULL |
|45332 |Mel |Blanc |909 |2022-05-25 19:31:47|NULL |
|621468|Bess |Flowers |672 |2022-05-25 19:31:47|NULL |
|283127|Tom |London |549 |2022-05-25 19:31:47|NULL |
+------+----------+------------+----------+-------------------+------------+
-
Сделаем так, чтобы наш любимый актёр Clicky McClickHouse появился ещё в 10 фильмах.
INSERT INTO imdb.roles
SELECT now() as created_at, 845466 as actor_id, rand(number) % 412320 as movie_id, 'Himself' as role
FROM system.numbers
LIMIT 10;
-
Повторно выполните команду dbt run из каталога imdb. Это обновит инкрементальную модель. После завершения запустите dbt snapshot, чтобы зафиксировать изменения.
clickhouse-user@clickhouse:~/imdb$ dbt run
13:46:14 Running with dbt=1.1.0
13:46:14 Found 1 model, 0 tests, 1 snapshot, 0 analyses, 181 macros, 0 operations, 0 seed files, 3 sources, 0 exposures, 0 metrics
13:46:14
13:46:15 Concurrency: 1 threads (target='dev')
13:46:15
13:46:15 1 of 1 START incremental model imdb_dbt.actor_summary....................... [RUN]
13:46:18 1 of 1 OK created incremental model imdb_dbt.actor_summary.................. [OK in 2.76s]
13:46:18
13:46:18 Finished running 1 incremental model in 3.73s.
13:46:18
13:46:18 Completed successfully
13:46:18
13:46:18 Done. PASS=1 WARN=0 ERROR=0 SKIP=0 TOTAL=1
clickhouse-user@clickhouse:~/imdb$ dbt snapshot
13:46:26 Running with dbt=1.1.0
13:46:26 Found 1 model, 0 tests, 1 snapshot, 0 analyses, 181 macros, 0 operations, 0 seed files, 3 sources, 0 exposures, 0 metrics
13:46:26
13:46:27 Concurrency: 1 threads (target='dev')
13:46:27
13:46:27 1 of 1 START snapshot snapshots.actor_summary_snapshot...................... [RUN]
13:46:31 1 of 1 OK snapshotted snapshots.actor_summary_snapshot...................... [OK in 4.05s]
13:46:31
13:46:31 Finished running 1 snapshot in 5.02s.
13:46:31
13:46:31 Completed successfully
13:46:31
13:46:31 Done. PASS=1 WARN=0 ERROR=0 SKIP=0 TOTAL=1
-
Если теперь выполнить запрос к нашему snapshot, обратите внимание, что у нас есть 2 строки для Clicky McClickHouse. У нашей предыдущей записи теперь установлено значение dbt_valid_to. Новая запись сохранена с тем же значением в столбце dbt_valid_from и значением dbt_valid_to, равным null. Если бы у нас появились новые строки, они также были бы добавлены к snapshot.
SELECT id, name, num_movies, dbt_valid_from, dbt_valid_to FROM snapshots.actor_summary_snapshot ORDER BY num_movies DESC LIMIT 5;
+------+----------+------------+----------+-------------------+-------------------+
|id |first_name|last_name |num_movies|dbt_valid_from |dbt_valid_to |
+------+----------+------------+----------+-------------------+-------------------+
|845467|Danny |DeBito |920 |2022-05-25 19:33:32|NULL |
|845466|Clicky |McClickHouse|920 |2022-05-25 19:34:37|NULL |
|845466|Clicky |McClickHouse|910 |2022-05-25 19:32:34|2022-05-25 19:34:37|
|45332 |Mel |Blanc |909 |2022-05-25 19:31:47|NULL |
|621468|Bess |Flowers |672 |2022-05-25 19:31:47|NULL |
+------+----------+------------+----------+-------------------+-------------------+
Более подробную информацию о снимках dbt см. по ссылке.
Использование seed-файлов
dbt предоставляет возможность загружать данные из CSV-файлов. Эта функциональность не подходит для загрузки больших экспортов базы данных и больше предназначена для небольших файлов, обычно используемых для таблиц кодов и словарей, например, для сопоставления кодов стран с названиями стран. В простом примере мы генерируем и затем загружаем список кодов жанров, используя функциональность seed.
-
Мы генерируем список кодов жанров из нашего существующего набора данных. Из каталога dbt используйте clickhouse-client, чтобы создать файл seeds/genre_codes.csv:
clickhouse-user@clickhouse:~/imdb$ clickhouse-client --password <password> --query
"SELECT genre, ucase(substring(genre, 1, 3)) as code FROM imdb.genres GROUP BY genre
LIMIT 100 FORMAT CSVWithNames" > seeds/genre_codes.csv
-
Выполните команду dbt seed. Это создаст новую таблицу genre_codes в нашей базе данных imdb_dbt (как определено в конфигурации схемы) с строками из нашего CSV-файла.
clickhouse-user@clickhouse:~/imdb$ dbt seed
17:03:23 Running with dbt=1.1.0
17:03:23 Found 1 model, 0 tests, 1 snapshot, 0 analyses, 181 macros, 0 operations, 1 seed file, 6 sources, 0 exposures, 0 metrics
17:03:23
17:03:24 Concurrency: 1 threads (target='dev')
17:03:24
17:03:24 1 of 1 START seed file imdb_dbt.genre_codes..................................... [RUN]
17:03:24 1 of 1 OK loaded seed file imdb_dbt.genre_codes................................. [INSERT 21 in 0.65s]
17:03:24
17:03:24 Finished running 1 seed in 1.62s.
17:03:24
17:03:24 Completed successfully
17:03:24
17:03:24 Done. PASS=1 WARN=0 ERROR=0 SKIP=0 TOTAL=1
-
Подтвердите, что они были загружены:
SELECT * FROM imdb_dbt.genre_codes LIMIT 10;
+-------+----+
|genre |code|
+-------+----+
|Drama |DRA |
|Romance|ROM |
|Short |SHO |
|Mystery|MYS |
|Adult |ADU |
|Family |FAM |
|Action |ACT |
|Sci-Fi |SCI |
|Horror |HOR |
|War |WAR |
+-------+----+=
В предыдущих руководствах затронута лишь небольшая часть функциональности dbt. Рекомендуем ознакомиться с отличной документацией dbt.